이 대회는 타이타닉호를 탄 승객들의 이름, 성별, 나이, 지불한 운임, 가족수 등 여러 정보를 주고, 각 승객이 살았는지 죽었는지 예측하는 경진대회. 훈련용 데이터에는 승객 정보와 생사여부가 모두 표기되어 있고 테스트용 데이터에는 승객 정보만 표기되어 있습니다. 훈련용 데이터로 모델을 훈련한 뒤 테스트용 데이터에 있는 승객의 정보를 기반으로 생사여부를 예측해야 함. 가장 기본적인 대회
훈련용 데이터인 train.csv로 모델 훈련
테스트용 데이터인 test.csv로 결과 예측/ 제출용 샘플 데이터인 gender_submission.csv형식에 맞게 제출
https://www.kaggle.com/competitions/titanic/code
Titanic - Machine Learning from Disaster | Kaggle
www.kaggle.com
설명
인공지능 기법을 사용하여 타이타닉 난파선에서 살아남은 승객을 예측하는 모델을 만듭니다.
생존과 관련된 여러 요소가 있지만 일부 사람들은 다른 사람들보다 생존 할 가능성이 더 높은 것으로 보입니다. 이 대회에서 우리는 “어떤 종류의 사람들이 살아남을 가능성이 더 높습니까?”라는 질문에 대답하는 예측 모델을 구축하여야 합니다
평가방법
승객 데이터 (예 : 이름, 연령, 성별, 사회 경제적 클래스 등) 사용하여 승객이 타이타닉 침몰에서 살아남았는지 예측하는 것이 임무입니다. 테스트 세트의 각각에 대해 변수의 0 또는 1 값을 예측해야 합니다.
어떤 데이터가 있나?
survival - 생존여부 ( 0 = No, 1 = Yes ) (0=사망, 1=생존)
pclass - 티켓 등급 ( 1 = 1st, 2 = 2nd, 3 = 3rd )
sibsp - 타이타닉에 승선한 형제자매 또는 배우자의 수
parch - 타이타닉에 승선한 부모 - 자식의 수
cabin - 선실 번호
embarked - 승선 항구 이름 ( C = Cherbourg, Q = Queenstown, S = Southampton )
1. 머신러닝 기본 환경 설정
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use ( 'seaborn-v0_8' )
sns. set ( font_scale= 2.5 )
import missingno as msno
#결측치 시각화
# ignore warnings
import warnings
warnings.filterwarnings ( 'ignore' )
%matplotlib inline
-import numpy as np: 행렬 단위로 수치데이터 관리, 이에 대해 연산 수행
-import pandas as pd: 행렬 단위로 데이터 객체 다룸, 대용량의 데이터 처리
-import matplotlib.pylot: 그래프 그리기
-import seaborn: 파이썬 시각화 라이브러리
-import missingno: 결측치 시각화 라이브러리
-import warnings.warnings.filterwarnings('ignore'): 코드를 작성할 때 보이는 경고문(빨간 줄)을 보이지 않게 해줌
**(반대로 improt warnings warnings.filterwarnings('always')를 작성하면 항상 보이게 해줌)
2. 데이터 불러오기
csv데이터 불러올 때 여러 방법이 있지만 이 방법이 제일 간단하다...
https://kimhongsi.tistory.com/entry/Google-Colab-%EC%BD%94%EB%9E%A9%EC%97%90%EC%84%9C-csv-%ED%8C%8C%EC%9D%BC-%EB%B6%88%EB%9F%AC%EC%98%A4%EA%B8%B0
(**나는 kaggle과 colab연동을 하지 못하여 그냥 데이터를 가져왔다..)
# 데이터 가져오기
df_train = pd.read_csv ( '/content/train.csv' )
df_test = pd.read_csv ( '/content/test.csv' )
submission = pd.read_csv ( '/content/gender_submission.csv' )
3. 어떤 데이터가 있는지 확인하기
df_train.head ( 5 )
PassengerIdSurvivedPclass Name Sex Age SibSp Parch Ticket FareCabinEmbarked01234
1
0
3
Braund, Mr. Owen Harris
male
22.0
1
0
A/5 21171
7.2500
NaN
S
2
1
1
Cumings, Mrs. John Bradley (Florence Briggs Th...
female
38.0
1
0
PC 17599
71.2833
C85
C
3
1
3
Heikkinen, Miss. Laina
female
26.0
0
0
STON/O2. 3101282
7.9250
NaN
S
4
1
1
Futrelle, Mrs. Jacques Heath (Lily May Peel)
female
35.0
1
0
113803
53.1000
C123
S
5
0
3
Allen, Mr. William Henry
male
35.0
0
0
373450
8.0500
NaN
S
-데이터이름.head(5) : 앞에 줄 5줄만 보여줌
-데이터이름.tail(5): 뒤에 줄 5줄만 보여줌
#나머지 데이터도 확인
df_test.head ( 5 )
print ( df_train.shape )
print ( df_test.shape )
> (891, 12) (418, 11)
-데이터이름.shape: 몇 행과 몇 열로 이루어져있는지 알려줌
EDA
4. 각 데이터의 결측값 확인하기
df_train.isna () . sum ()
df_test.isna().sum()
>결과값
5. 결측치 시각화하기
(*꼭 필요한 과정 x 얼마나 결측치를 잘 처리하는지가 더 중요하다)
*참고 블로그
https://blog.naver.com/bosongmoon/221778045509
50. 파이썬 - missingno(msno) 활용해 결측치 시각화하기 / 결측치 확인하기
* 본 포스팅은 주피터 노트북을 기반으로 진행 데이터 불러오기 # 사용할 데이터는 타이타닉 데이터이다. ...
blog.naver.com
msno.bar ( df_train.sample ( 500 ), log = True )
>결과값: df_train데이터에서 무작위로 500개의 샘플을 이용하여 log로 처리를 해주었다.
>누락된 값이 있는 것들로 보아 저 빈칸들이 결측값들이겠구나 생각할 수 있다.
두번째 코드
msno.matrix ( df=df_train.iloc [:, :], figsize = ( 8 , 8 ), color = ( 0.8 , 0.5 , 0.2 ))
df_train.iloc[:, :] 은 모든 행과 모든 열을 선택하겠다
>아하 군데군데 흰색이 있는 것으로 보아 누락된 값들이 있겠구나!
6. ERD- 각 자료 분석하기
crosstab 교차분석은 두가지 이상의 facotr에 대한 간단한 교차표를 작성한다.
*참고블로그
https://zzinnam.com/pandas-crosstab-%ED%95%A8%EC%88%98-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0/
pd.crosstab ( df_train [ 'Pclass' ], df_train [ 'Survived' ], margins= True )
crosstab('행에 들어갈 데이터','열에 들어갈 데이터', margins=True '합계' )
>행에 들어가는 것이 Pclass라서 각 자리의 갯수가 들어갔고, 열에는 0과 1로 생존과 죽음을 나타내었다.
7. 시각화를 해보자
1.Pclass 분석
https://blog.naver.com/tmdghlrla/223267381412
[Python] matplot 라이브러리 차트그리기1 (plt.plot, plt.countplot, plt.pie )
정리 Plot 가장기본적인 방식 x와 y에 같은 값을 넣고 y=x 그래프를 그리려고한다. plt.savefig(&#x...
blog.naver.com
counterplot-몇 개 있는지 사용할 때 유용함
y_position= 1.02
plt.plot ( figsize= ( 18 , 8 ))
sns.countplot ( x= 'Pclass' , hue= 'Survived' , data=df_train )
plt.title ( "Pclass: Survived vs Dead" , y=y_position )
plt.show ()
>어떤 자리일수록 생존했는지, 혹은 사망했는지 알 수 있다.
2. 성별분석
**항목별 개수를 구하는 library : value_counts로 그래프 생성한다 / pandas에서 항목별 개수를 세고 바로 히스토그램 그릴 수 있다.
*value_counts 참고블로그
https://zzinnam.tistory.com/entry/pandas-valuecounts-%ED%95%A8%EC%88%98
y_position= 1.02
plt.plot ( figsize= ( 18 , 8 ))
df_train [ 'Sex' ] .value_counts ()
sns.countplot ( x= 'Sex' , hue= 'Survived' , data=df_train )
plt.title ( "Sex:Survived vs Dead" , y=y_position )
plt.ylabel ( "Count" )
plt.show ()
#그룹화
###exData안의 "성별"에 따른 "Grade"값 확인
exData.groupby("Sex")["Grade"].value_counts()
3. 나이분석
나이는 이분법적인 범주형 자료가 아니라 continuous 한 데이터이기 때문에 범위 데이터로 지정해주었다.
#[Age] col 내의 최대값을 구한다
>>>>80인걸 확인!
change_age_range_survival_rate = []
for i in range ( 1 , 80 ):
change_age_range_survival_rate.append ( df_train [ df_train [ 'Age' ] < i ][ 'Survived' ] . sum () / len ( df_train [ df_train [ 'Age' ] < i ][ 'Survived' ]))
plt.figure ( figsize= ( 7 , 7 ))
plt.plot ( change_age_range_survival_rate )
plt.title ( 'Survival rate change depending on range of Age' , y= 1.02 )
plt.ylabel ( 'Survival rate' )
plt.xlabel ( 'Range of Age(0~x)' )
plt.show ()
4. Embarked 분석
**참고
https://bigdaheta.tistory.com/44
[pandas] 4. 데이터 정렬 (sort_values, sort_index, by, ascending)
01. 데이터 값을 기준으로 데이터 정렬 : sort_values( ) 〰️ sort_values( ) 사용 방법 import pandas as pd df1 = pd.read_csv('파일명') df1.head() 먼저 판다스(pandas) 라이브러리를 임포트(import)하고, 사용할 데이터
bigdaheta.tistory.com
4-1. sort_values
-sort_values:데이터 값을 기준으로 데이터 정렬
-특정 칼럼의 값 정렬
df['칼럼명'].sort_values()
# 데이터 값은 기본적으로 오름차순 정렬
#결측치가 있다면 그 값은 맨 마지막에 위치
-col을 기준으로 정렬
df.sort_values(by=['정렬의 기준이 되는 칼럼'])
ex) df1에서 나이가 어린 순서대로, 지불한 금액은 큰 순서대로 정렬해라
df1.sort_values(by=['Age','Fare'],ascending=[True,False])
4-2. subplot(): 현재 조작중인 figure에 sub plot을 만들어준다.
plt.subplot(nrows,ncols,index)
#nrows는 행의 수, ncols는 열의 수, index는 위치
df_train [[ 'Embarked' , 'Survived' ]] .groupby ([ 'Embarked' ]) .mean () .sort_values ( by= 'Survived' , ascending= False ) .plot.bar ( figsize= ( 7 , 7 ))
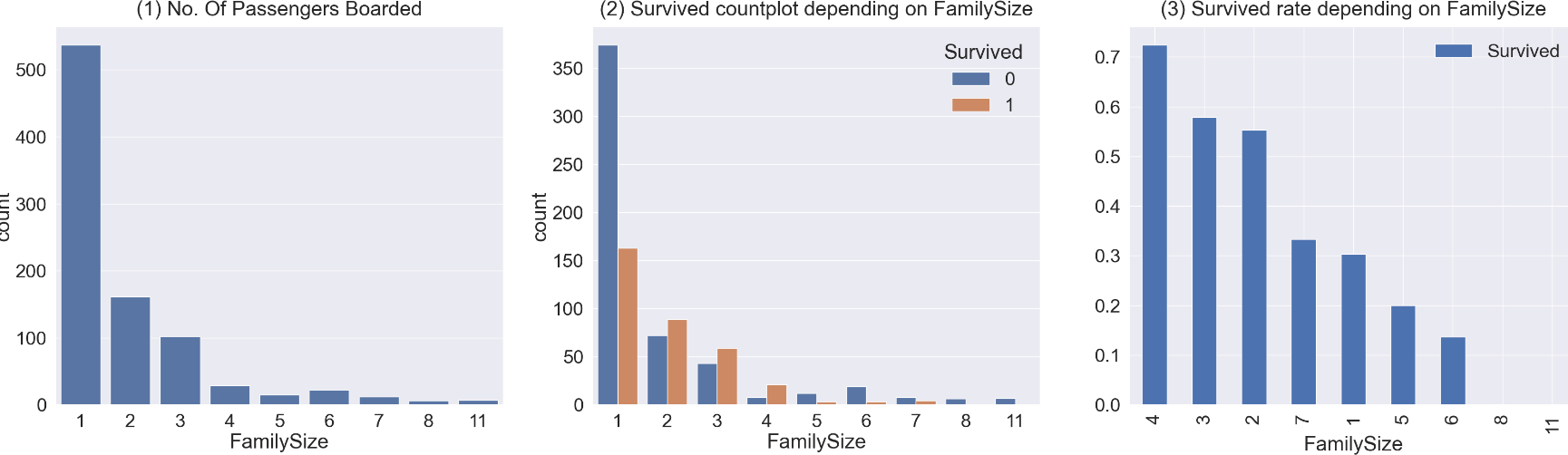
5. Family 분석
FamiilySize에 대한 col이 없어서 SibSp 와 Parch를 이용해서 새로운 col을 만들어주었다.
+subplot을 이용하여 여러 그래프를 그려주었다.
df_train [ 'FamilySize' ] = df_train [ 'SibSp' ] + df_train [ 'Parch' ] + 1 # 자신을 포함해야하니 1을 더함
df_test [ 'FamilySize' ] = df_test [ 'SibSp' ] + df_test [ 'Parch' ] + 1 # 자신을 포함해야하니 1을 더함
print ( "Maximum size of Family: " , df_train [ 'FamilySize' ] . max ())
print ( "Minimum size of Family: " , df_train [ 'FamilySize' ] . min ())
f , ax=plt.subplots ( 1 , 3 , figsize= ( 40 , 10 ))
sns.countplot ( x= 'FamilySize' , data=df_train , ax=ax [ 0 ])
ax [ 0 ] .set_title ( '(1) No. Of Passengers Boarded' , y= 1.02 )
sns.countplot ( x= 'FamilySize' , hue= 'Survived' , data=df_train , ax=ax [ 1 ])
ax [ 1 ] .set_title ( '(2) Survived countplot depending on FamilySize' , y= 1.02 )
df_train [[ 'FamilySize' , 'Survived' ]] .groupby ([ 'FamilySize' ], as_index= True ) .mean () .sort_values ( by= 'Survived' , ascending= False ) .plot.bar ( ax=ax [ 2 ])
ax [ 2 ] .set_title ( '(3) Survived rate depending on FamilySize' , y= 1.02 )
#얘는 Familysize+ Survived 합쳐진 그래프가 생성되는거다.
plt.subplots_adjust ( wspace= 0.2 , hspace= 0.5 )
plt.show ()
6. Fare분석
-수치형 데이터의 분포 표시: distplot(히스토그램을 그려줌)/ 단 결측치가 있으면 그릴 수 없음
연속적인 데이터의 값 표시
(*scatterplot은 x,y둘 다 수치형 데이터 일 때 사용)
-hist=False: 선만 나옴
-legend: 범례 추가( legend(loc="best") 범례를 최적의 위치에 자동으로 배치하라는 의미
sns.distplot ( df_train [ 'Fare' ], color= 'b' , label= 'Skewness : {:.2f}' . format ( df_train [ 'Fare' ] .skew ()))
plt.legend ( loc= "best" )
df_train['Fare'].skew() 는 열의 왜도 값 계산
(*skew는 왜도 또는 , 평균에 대해 최빈값이 얼마나 치우쳐져있는지를 나타내는 척도임 는 우측으로 치우칠수록 음의값, 좌측으로 치우칠수록 양의 값)
df_test.loc [ df_test.Fare.isnull (), 'Fare' ] = df_test [ 'Fare' ] .mean () # test set에 있는 nan value 를 평균값으로 치환합니다.
df_train [ 'Fare' ] = df_train [ 'Fare' ] . map ( lambda i : np.log ( i ) if i > 0 else 0 ) # Log를 씌어 첨도를 조정함
df_test [ 'Fare' ] = df_test [ 'Fare' ] . map ( lambda i : np.log ( i ) if i > 0 else 0 )
fig , ax = plt.subplots ( 1 , 1 , figsize= ( 8 , 8 ))
g = sns.distplot ( df_train [ 'Fare' ], color= 'b' , label= 'Skewness : {:.2f}' . format ( df_train [ 'Fare' ] .skew ()), ax=ax ) # 왜도 조정
g = g.legend ( loc= 'best' )
왜도가 너무 낮아 조정해주었다!--!
8. Feature Engineering
>> 데이터를 분석하거나 알고리즘을 적용하기 위해, 머신러닝 작동을 위해 데이터의 도메인 지식을 활용하여 변수를 가공하고 간단명료하게 만드는 것
연속형 변수를 범주형으로 만들거나, 똑같은 구간별로 나누는 방법등이 있다.
즉 앞에서 분석한 데이터들을 가지고 머신러닝을 적용시키기 위해 유의미한 데이터만 뽑아온다.
(*그나저나 이 블로그 굉장히 귀엽다! 데이터프레임 꾸미기!!! ㅎㅎ)
https://abluesnake.tistory.com/168
[pandas] style로 데꾸(데이터프레임 꾸미기)하는 방법
들어가며 오랜만에 파이썬을 사용하다가 유용해보이는 기능을 발견하여 공유하고자 합니다. 바로 pandas의 style 기능입니다. 데이터 분석을 하면 데이터프레임에 찍힌 숫자나 문자와 같은 값들을
abluesnake.tistory.com
df_train [ 'Initial' ] = df_train.Name. str .extract ( '([A-Za-z]+)\.' )
df_test [ 'Initial' ] = df_test.Name. str .extract ( '([A-Za-z]+)\.' )
pd.crosstab ( df_train [ 'Initial' ], df_train [ 'Sex' ])
이름들을 가져와서 initial 이라는 새로운 col을 만들어준다.
이 이름들과 성을 엮는다.
>> 생각보다 너무 길어서 보기에 불편하다 ㅠ.
pd.crosstab ( df_train [ 'Initial' ], df_train [ 'Sex' ]) .T
행과 열을 바꾸어주어 보기 예쁘게 해주었다. 이제 데꾸를 해보자!
g=pd.crosstab ( df_train [ 'Initial' ], df_train [ 'Sex' ]) .T
g.style.highlight_max ( axis= 0 , color= 'lightblue' )
axis=0: 열을 기준으로 max
axis=1: 행을 기준으로 max
좀 예뻐졌당
df_train [ 'Initial' ] .replace ([ 'Mlle' , 'Mme' , 'Ms' , 'Dr' , 'Major' , 'Lady' , 'Countess' , 'Jonkheer' , 'Col' , 'Rev' , 'Capt' , 'Sir' , 'Don' , 'Dona' ],
[ 'Miss' , 'Miss' , 'Miss' , 'Mr' , 'Mr' , 'Mrs' , 'Mrs' , 'Other' , 'Other' , 'Other' , 'Mr' , 'Mr' , 'Mr' , 'Mr' ], inplace= True )
df_test [ 'Initial' ] .replace ([ 'Mlle' , 'Mme' , 'Ms' , 'Dr' , 'Major' , 'Lady' , 'Countess' , 'Jonkheer' , 'Col' , 'Rev' , 'Capt' , 'Sir' , 'Don' , 'Dona' ],
[ 'Miss' , 'Miss' , 'Miss' , 'Mr' , 'Mr' , 'Mrs' , 'Mrs' , 'Other' , 'Other' , 'Other' , 'Mr' , 'Mr' , 'Mr' , 'Mr' ], inplace= True )
여기 이름들에는 성별을 나타내어주는 성들이 포함되어있다. 이를 묶어서 표현해주겠다!
여기서 inplace=True라는 것은 해당 연산이 데이터프레임을 직접 수정한다는 것이다. 직접 변경하여 원본 데이터프레임이 수정된다. 만약 inplace=False 또는 생략하면 연산의 결과가 새로운 데이터프레임으로 반환되어 원본 데이터프레임은 변경되지 않는다.
원본 데이터에서 이름 col이 잘 묶인 것을 볼 수 있다. 굿굿
df_train [[ 'Survived' , 'Pclass' , 'Age' , 'Initial' ]] .groupby ( 'Initial' ) .mean ()
df_train.groupby ( 'Initial' )[ 'Survived' ] .mean () .plot.bar ()
9.feature engineering- 결측값 처리
9-1. Age
이제 여기서 아까 확인했던 Age 의 결측값을 처리해 줄 것이다.
# Mean으로 NaN값 대체
df_train.loc [( df_train.Age.isnull ()) & ( df_train.Initial== 'Mr' ), 'Age' ] = 33
df_train.loc [( df_train.Age.isnull ()) & ( df_train.Initial== 'Mrs' ), 'Age' ] = 36
df_train.loc [( df_train.Age.isnull ()) & ( df_train.Initial== 'Master' ), 'Age' ] = 5
df_train.loc [( df_train.Age.isnull ()) & ( df_train.Initial== 'Miss' ), 'Age' ] = 22
df_train.loc [( df_train.Age.isnull ()) & ( df_train.Initial== 'Other' ), 'Age' ] = 46
df_test.loc [( df_test.Age.isnull ()) & ( df_test.Initial== 'Mr' ), 'Age' ] = 33
df_test.loc [( df_test.Age.isnull ()) & ( df_test.Initial== 'Mrs' ), 'Age' ] = 36
df_test.loc [( df_test.Age.isnull ()) & ( df_test.Initial== 'Master' ), 'Age' ] = 5
df_test.loc [( df_test.Age.isnull ()) & ( df_test.Initial== 'Miss' ), 'Age' ] = 22
df_test.loc [( df_test.Age.isnull ()) & ( df_test.Initial== 'Other' ), 'Age' ] = 46
Mr, Mrs, Master,Miss, Other그룹에 속하는 행들의 'Age'열이 결측값인 경우에, 각각의 평균 나이로 대체 한다.
9-2. Embarked
sum ( df_train [ 'Embarked' ] .isnull ())
>>2
df_train [ 'Embarked' ] .fillna ( 'S' , inplace= True )
Embarked의 결측값은 2개라서 결측값이 영향을 줄 것 같지 않아 그냥 최빈값이었던 'S'로 대체한다.
10. feature engineering- 데이터를 category로 묶어버리기
10-1. Age
연속형 데이터는 카테고리형으로 묶지 않으면 머신러닝이 파악하기 어렵다잉 ㅠ
def category_age ( x ) :
if x < 10 :
return 0
elif x < 20 :
return 1
elif x < 30 :
return 2
elif x < 40 :
return 3
elif x < 50 :
return 4
elif x < 60 :
return 5
elif x < 70 :
return 6
else :
return 7
df_train [ 'Age_cat' ] = df_train [ 'Age' ] .apply ( category_age )
10대 20 대 이런식으로 묶는다. 이때 함수를 만들고 apply를 사용하여 age_cat이라는 새로운 변수에 저장한다.
df_train.drop ([ 'Age' ], axis= 1 , inplace= True )
Age_cat만 남겨두기 위해 Age를 갖다 버린다.
10-2. Embarked
df_train.initial.unique ()
>>Mr. Mrs. Miss.Master.Other
이렇게 나오는 것들을 수치형 데이터로 표현하게끔 바꾸어보자.
df_train [ 'Initial' ] . map ({ 'Master' : 0 , 'Miss' : 1 , 'Mr' : 2 , 'Mrs' : 3 , 'Other' : 4 })
df_train [ 'Embarked' ] = df_train [ 'Embarked' ] . map ({ 'C' : 0 , 'Q' : 1 , 'S' : 2 })
df_test [ 'Embarked' ] = df_test [ 'Embarked' ] . map ({ 'C' : 0 , 'Q' : 1 , 'S' : 2 })
df_train [ 'Sex' ] = df_train [ 'Sex' ] . map ({ 'female' : 0 , 'male' : 1 })
df_test [ 'Sex' ] = df_test [ 'Sex' ] . map ({ 'female' : 0 , 'male' : 1 })
Initial, Embarked와 Sex모두 수치형으로 바꾸어줌!
상관관계를 분석해보자
heatmap_data = df_train [[ 'Survived' , 'Pclass' , 'Sex' , 'Fare' , 'Embarked' , 'FamilySize' , 'Age_cat' ]]
colormap = plt.cm.RdBu
plt.figure ( figsize= ( 14 , 12 ))
plt.title ( 'Pearson Correlation of Features' , y= 1.05 , size= 15 )
sns.heatmap ( heatmap_data.astype ( float ) .corr (), linewidths= 0.1 , vmax= 1.0 ,
square= True , cmap=colormap , linecolor= 'white' , annot= True , annot_kws= { "size" : 16 })
del heatmap_data
corr(): 상관관계를 나타내줘!
열들 간의 상관관계를 보여줌. 숫자가 높을수록 강한 양의 상관관계, 낮을수록 강한 음의 상관관계
11. One-hot encoding
위의 수치화된 카테고리를 (0,1)로 이루어진 5차원의 벡터로 만들어준다. 물론 수치화된 데이터 그대로 넣어도 되지만 이렇게 해서 모델의 성능을 더 높일 수 있다.
df_train = pd.get_dummies ( df_train , columns= [ 'Initial' ], prefix= 'Initial' )
df_test = pd.get_dummies ( df_test , columns= [ 'Initial' ], prefix= 'Initial' )
initial을 기준으로 더미 변수 생성
prefix=initial: 생성된 더미 변수들의 이름은 initial을 접두사로 하고 각각의 카테고리를 나타내는 이름이 뒤에 추가됨
df_train = pd.get_dummies ( df_train , columns= [ 'Embarked' ], prefix= 'Embarked' )
df_test = pd.get_dummies ( df_test , columns= [ 'Embarked' ], prefix= 'Embarked' )
이미 유의미한 데이터들은 카테고리로 묶어주었기 때문에 불필요한 데이터는 삭제하도록 한다.
df_train.drop ([ 'PassengerId' , 'Name' , 'SibSp' , 'Parch' , 'Ticket' , 'Cabin' ], axis= 1 , inplace= True )
df_test.drop ([ 'PassengerId' , 'Name' , 'SibSp' , 'Parch' , 'Ticket' , 'Cabin' ], axis= 1 , inplace= True )
12. 머신러닝 적용
#지도학습-우리가 학습하는 레이블을 주니까
#importing all the required ML packages
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics # 모델의 평가를 위해
from sklearn.model_selection import train_test_split
*sklearn- 거의 모든 머신러닝의 모델들이 들어있음
우리는 여기서 데이터들을 통하여 머신러닝을 학습시키고 새로운 test_data를 input으로 넣어 각 샘플을 새롭게 예측하게 할 것이다.
X_train = df_train.drop ( 'Survived' , axis= 1 ) .values
target_label = df_train [ 'Survived' ] .values
X_test = df_test.values
# data split
X_tr , X_vld , y_tr , y_vld = train_test_split ( X_train , target_label , test_size= 0.3 , random_state= 1234 )
model = RandomForestClassifier ()
model.fit ( X_tr , y_tr )
prediction = model.predict ( X_vld )
print ( '총 {}명 중 {:.2f}% 정확도로 생존을 맞춤' . format ( y_vld.shape [ 0 ], 100 * metrics.accuracy_score ( prediction , y_vld )))
-fit: training 시킨다.
from pandas import Series
feature_importance = model.feature_importances_
Series_feat_imp = Series ( feature_importance , index=df_test.columns )
plt.figure ( figsize= ( 8 , 8 ))
Series_feat_imp.sort_values ( ascending= True ) .plot.barh ()
plt.xlabel ( 'Feature importance' )
plt.ylabel ( 'Feature' )
plt.show ()
-feature_importance: 모델이 예측을 할 때 어떤 값에 가장 영향을 받는가
모든 feature가 가지고 있음
음~ Fare가 가장 많은 영향을 주는군!
13. 실제 Prediction&Test set
prediction = model.predict ( X_test )
#예측을 했다!
submission [ 'Survived' ] = prediction
submission.to_csv ( './titanic/my_first_submission.csv' , index= False)
my_result = pd.read_csv ( './titanic/my_first_submission.csv' ) # public score is 0.736
my_result.head ( 10 )
my_first_submission에 새로운 데이터프레임으로 저장하는 것!
> 이 상태로 제출하면 된다!!
참고
https://www.youtube.com/watch?v=4SIKWBjLUKM